
In this article, you’ll learn:
Updated August 2022
No doubt, we’re spoiled for choice with today’s variety of file storage. Cloud services are the most popular on the market thanks to their accessibility and ease of use. As estimated, there exist over 2300 million cloud storage users across the globe. This figure is expected to grow even further.
Scalable infrastructure and security measures make Amazon S3 a top media library for many.
The top choices come with caveats though. Amazon's object system can complicate the onboarding process for new users. With this article, we’re going to tell you things to be on the lookout for when going for Amazon S3.
As we have recently built DAM integration with Amazon at Pics.io, uploading and managing files on S3 became really important for our users. So here we are, bringing benefit to everyone who needs this info to make working with S3 a piece of cake for you.
Amazon S3 Terminology
As a new Amazon user, you may be puzzled when you first open your account. Where is the traditional file and folder organization? What is a secret key and why are my precious files stored in buckets?
Here is a short list of terms you might want to know before even signing in to your account:
- AWS (Amazon Web Services) Management Console. Web-based application through which you access and manage cloud storage. You’ll need your user name & password to sign in to your account.
- Root user vs. IAM (Identity and Access Management) user. There are two types of users in AWS. The owner (root user) and users with certain roles and access privileges (IAM users). For security purposes, Amazon recommends reducing the use of root user credentials. Instead, you can create an IAM user and grant them full access.

- Access Key ID and Secret Key. Besides console access, there is also programmatic access. To make those calls you'll need WS access keys.

- Bucket. In your Amazon S3 Console, you create buckets - parent folder for assets and their metadata. Amazon S3 gives 100 buckets per account, but you can increase this limit by up to 1000 buckets for an extra charge.

Bucket = Object 1 + Object 2 + Object 3
- Object. We store objects in buckets that consist of files and their metadata. An object can be any kind of file you need to upload: a text file, an image, video, audio, and so on. The size limit for uploads is 160 GB.

Object = file + metadata (optionally)
- Folders. You can group your objects by folders. Amazon S3 has a flat file system. A flat hierarchy is different from a traditional one with directories and subdirectories. For example, you add a project name + client name + due date so you won’t meet the same name across the storage.

- Region. Amazon S3 buckets are region-specific. This means you choose the location where you want the company to store your assets. Objects in the bucket won’t leave their location unless you transfer them to a different region.

- Key names & prefixes. Key names refer to object names. Together with prefixes, they help you access the needed file quicker and easier. Let’s say you store photo1 in folder1 in your bucket. You can search for files by entering bucket/folder1/photo1 instead of opening folders and buckets.

Getting started with Amazon S3
Creating Amazon S3 Bucket
After you’ve signed in to your AWS Console, it’s time to explore your user account. The first thing you do is to create an Amazon S3 bucket.
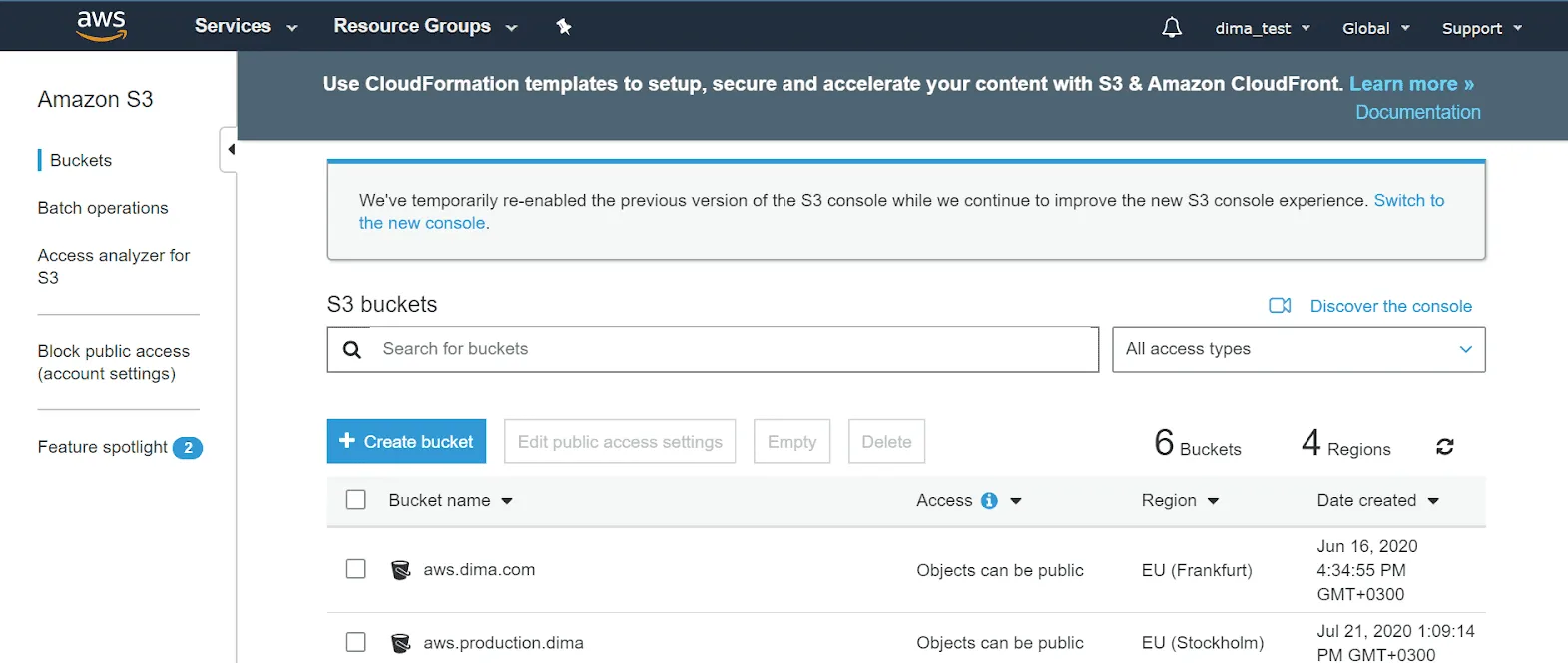
Here you need to state your bucket name and location where you want Amazon to store your bucket and its content. The bucket name must:
- have a unique name;
- be between 3 and 63 characters;
- contain only lowercase characters.
As for the region, the storage allows you to create a bucket in the location you want. And the best idea is to choose the one that is the closest to you. In this way, you won’t only reduce response time but will cut costs and meet regulatory requirements.
What else can I do with my bucket?
1) Permissions
In the same menu, you also set permissions and configure options. Depending on the roles in your team, you decide who will create, edit, and delete objects in your bucket.
2) Public vs. individual access
Don't choose public access unless you need to share files with many clients or partners. You can always make particular files publicly accessible to others.
3) Versioning
Enable versioning if you’re planning to store different revisions of the same object. Let’s say you’re designing a new logo for your marketing campaign. There will be many updates to your file when you experiment with the color palette or elaborate on the font.
With versioning, revisions have one key. You access them all at once when accessing the object. Versioning can also help if somebody deleted or edited a file by mistake, as you can revert to the correct version.
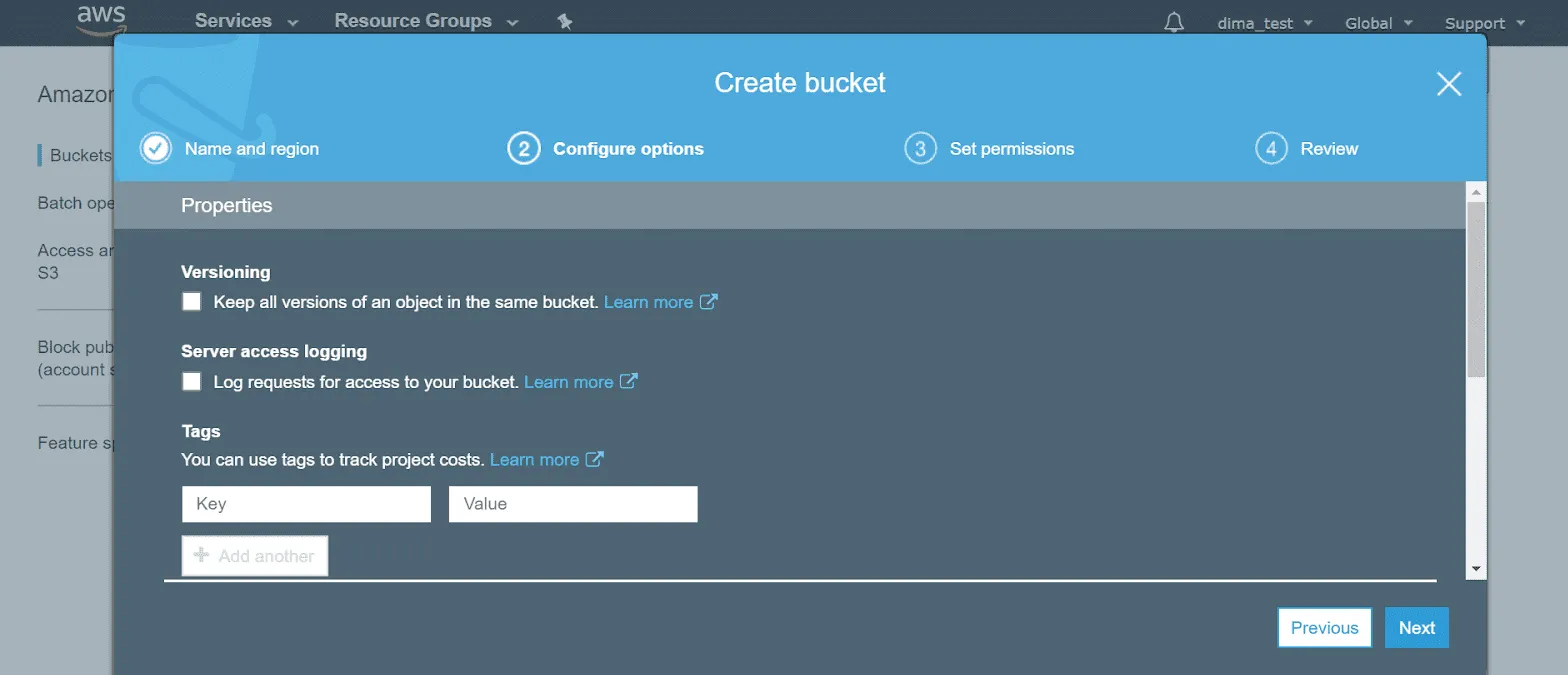
4) Server vs. object access logging
Check server access logging if you want to track requests made in a bucket. Access log reports come in handy to you in times of audits and as a safety precaution.
You can also try more advanced object-level logging. On this occasion, you’re free to filter events to be logged, and you track them in CloudTrail - a separate AWS auditing service.
5) Encryption
Encrypt your files if you want to additionally secure your data. When you encrypt data, users can only access it with a password and decryption key. It's a good measure for those that security concerns or requirements. S3 lets you choose the default encryption when you create a new bucket.
Getting inside the bucket
How to upload your files to Amazon S3?
We store our objects in the bucket and use folders if we need to group our files. To upload data to S3 bucket, click upload and select the files that you need. Click on create a folder if you need to group your objects in folders.
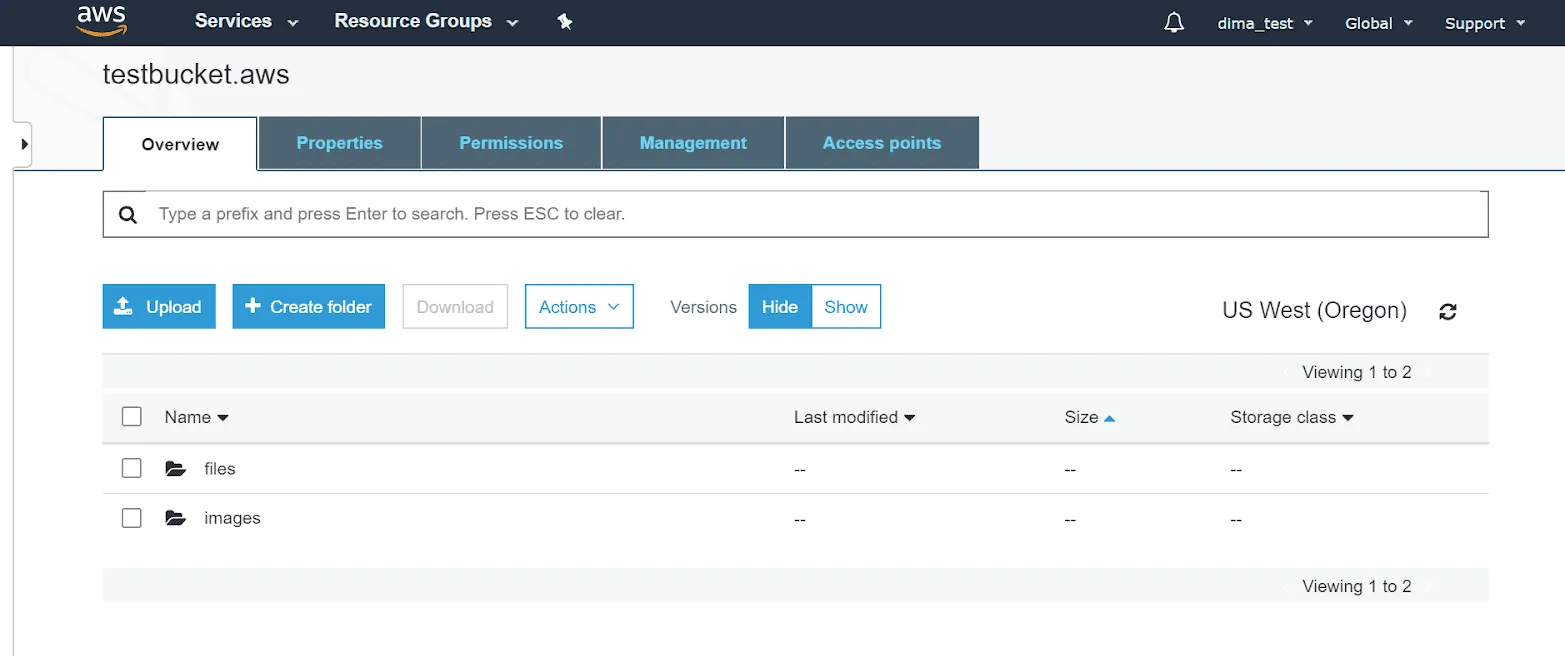
Mind that if you want to upload an entire folder, you can only do it with drag and drop. It still simplifies the task if you need to upload a broad scope of files and reflect their structure. With folder upload, Amazon S3 mirrors its structure and uploads all the subfolders.
What else should I know when uploading objects to S3 storage?
As there is no traditional filesystem we won’t speak about names as filenames anymore. This is why when you upload a new object, you won’t even have the possibility to choose a name for it.
But to compensate for non-existing filenames, the service uses an object key (or key name) which uniquely defines an object in the bucket.
What are other configuration options during the upload? As with buckets, you can use encryption to secure your data and manage public permissions. You can also make a particular file accessible to a certain user or user.
Choose storage classes based on how often you’re planning to access your data. S3 Standard (the default type) is for critical, non-reproducible data you’re going to manage on a regular basis.
S3 Tags vs. Metadata
Apart from a key (and data), each S3 object has metadata you set when uploading it. In brief, this is extra information about the object like creation data or author. Metadata storage uses a key-value system. Key helps to identify an object, and value is the object itself.
Content length or file type are the keys when we’re referring to these kinds of metadata. Their values will be the object size in bytes and different file types. PDF, text, video, audio, or any other format you can think about.
You can add tags to your files that help to search, organize, and manage access to your objects. Tags are the same key-value pairs, and they’re like metadata, but with some differences.
An object in S3 is invariable, the same as its metadata. The AWS Console allows you “to edit” metadata, but it doesn’t actually do that. What happens is that each time you change an object, you create its new version.
The situation is different with tags. Tags are extra, “subresource” information about an object. Since they’re managed separately, you won’t change a file when adding tags to it. You can choose up to 10 tags per object in S3.
How to Upload Object that has Metadata?
Uploading an object with metadata to your S3 may feel a bit tricky as you need to do it without GUI.
One way to upload such an object is through the AWS management console. You can find the code snippet you would need to input on AWS's official website.
Folders as a means of grouping objects
How do we use folders in S3?
Buckets and objects play central roles in S3 storage. But this is not the case with folders. Folders compensate for the absent file hierarchy to improve file management and access.
In Amazon S3, folders help you to find your files thanks to prefixes (located before the key name). Let’s say you create a folder named Images, and there you store an object with the key name images/photo1.jpg. “Images” is the prefix in this case. “/” is the delimiter, automatically added by the system (avoid them in your folder names). The more folders and subfolders you create, the more prefixes your file will get.
And so you can use these prefixes to access your data. Just type one or more prefixes into the S3 search engine to filter your searches.
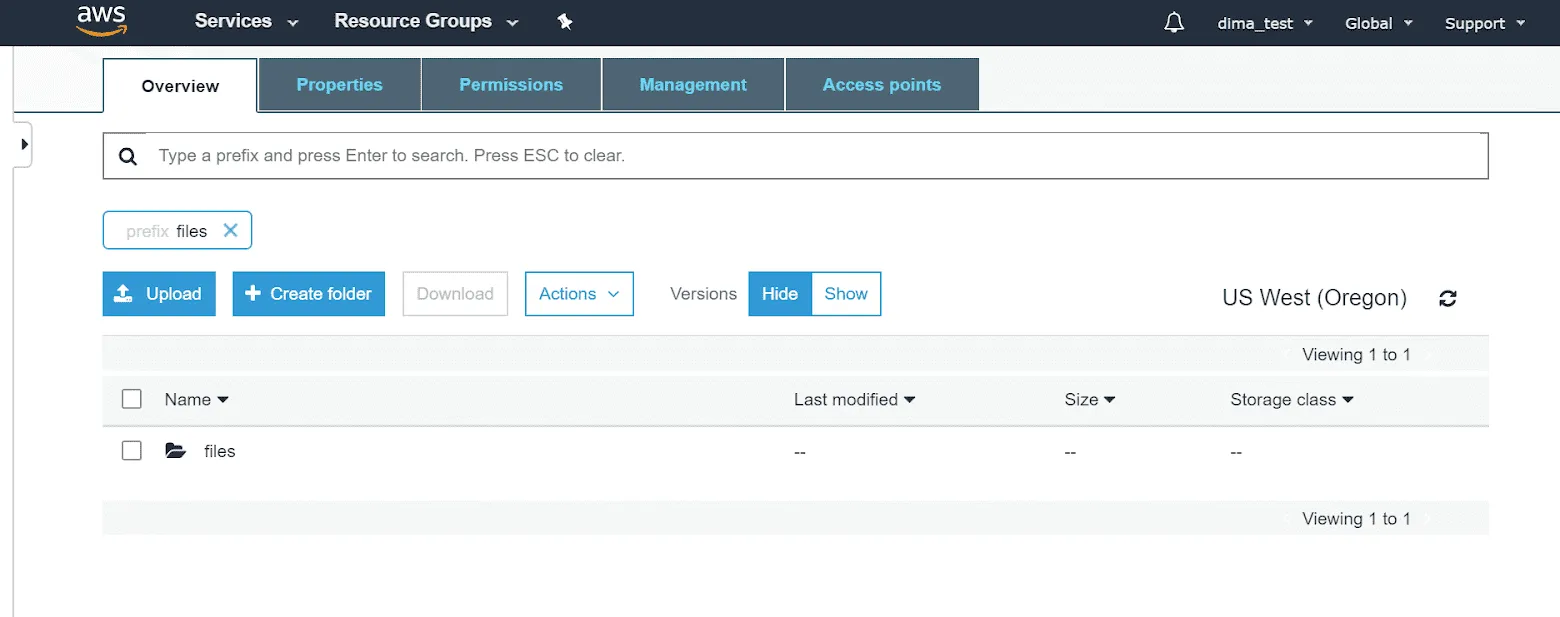
Actions with folders and objects
What you can do with your files and folders is pretty standard in Amazon S3 storage. You can create new folders, delete them, make them public, copy, and move them. You can also change their metadata, encryption, storage class, and tags. No renaming option is available.
Your interaction with objects won’t be very different. With Amazon S3, you’ll have no problem with uploading and copying objects. Plus, you can open your assets, move, download, and delete them (in different formats if needed).
Recovering deleted objects can be especially useful in case of system failures. Mind that “undeleting” objects is possible only in buckets with enabled versioning.
S3 Folder Structure Best Practices
Although it's ultimately up to you, there are a few things we would recommend when using folders.
First, you need to group related files together in separate subfolders. It would be best to avoid having multiple top-level folders. Still, it's best not to go too crazy on the subfolders as it doesn't add too much efficiency; only extra clicks.
Using descriptive names, meanwhile, can help with organizational structure and help you find folders you need long after you've forgotten why you have made them.
Getting back to upload again: Moving big data to Amazon S3
Uploading assets to Amazon S3 should not cause any difficulties. And it is so if we’re speaking about small-scale data. But what if your digital library extends to 1000 files or 10 000, or a million? Can you imagine you drag’n’drop these files or point-and-click them?
What a waste of time it could be! Fortunately, there are other, easier and faster ways to move massive data to your S3 storage…
Online tools
1) Direct Connect is an excellent solution for transferring large amounts of data. Its idea is to create a direct connection between your on-premise data sources and Amazon’s network. In this way, you bypass any obstacles created by your internet provider and web traffic and move your data quicker and easier.
You can request a connection in the AWS Console. Choose the region you want to use, set the number of ports, and their speed - and you can apply the solution.
When to use this solution?
- When you need to transfer large-scale data, and your Internet connection is slow.
- When you’re eager to reduce costs and achieve a more consistent network experience.
2) AWS Data Sync is very much like Direct Connect but is more sophisticated, with improved management and automation options. For example, AWS Data Sync allows you to track your transfers, schedule particular processes, adapt speed and bandwidth.
But a more advanced solution also means more complex transfers, doesn’t it? So users with limited knowledge in coding may find Data Sync too difficult.
When to use this solution?
- When you need extra automation for your data transfers to cut costs. Choose Data Sync if you want to filter your data migration, picking which folders/files to move first.
- When you work in a large enterprise, your data transfer will be completed under the supervision of developers.
3) Amazon S3 Transfer Acceleration was designed to speed up your data migration processes to S3 storage specifically. The solution works perfectly for data transfers across long physical distances.
When to use this solution?
- When you need a fast transfer and/or for a longer distance.
- When you have to move your data from one bucket only.
4) Amazon Kinesis Firehose is a real-time data migration tool you enable through the AWS Console. The service is good due to its easy-peasy interface - you set up the delivery in a few clicks. Plus, it’s more cost-efficient than other Amazon solutions as you pay not for the service but for the amount of data you transfer.
When to use this solution?
- When you’re looking for a streaming data migration tool.
- When you don’t want to waste your time on administration.
- When you’re planning to cut costs by means of paying as you go.
5) Tsunami UDP is one of a few free of charge solutions available to move big data to Amazon S3. It doesn’t work online yet, so you’ll have to download and install the tool. Plus, the basic knowledge in coding is necessary to work with this solution.
When to use this solution?
- When your budget is limited, but you still need to move large-scale data to your S3 storage.
- When you need to transfer files only (the solution doesn’t support moving folders and subfolders).
- When you don’t own any sensitive data: Tsunami UDP doesn’t encrypt your data.
6) Pics.io Data Migration is a new service delivered by Pics.io DAM. Choose this option if you need to transfer big data (and metadata!) to your AWS storage but don’t want to go into trouble by doing everything on your own.
When to use this solution?
- When you need to migrate your data from one source to another. It could be another cloud storage to Amazon S3. Or moving files between within your buckets.
- When you want to complete migration quickly & easily. In this case, you contact the Pics.io support team, grant a few permissions, & your DAM solution takes care of the rest.
- When you’re planning to move metadata together with your files. This allows you to preserve your folder structure, transfer keywords, file descriptions, and so on.
- When you care about the security of your information. Pics.io will complete the upload in the safest way possible.
Offline tools
7) AWS Import/Export Disk is an offline data transfer solution. Here you upload your data to a portable device and ship it to AWS. Then the company moves the data to your storage directly using its high-speed internal network. As a rule, this happens the next business day when Amazon receives your device. As soon as the export/import is completed, the company sends back your external hard drive.
When to use this solution?
- When preparing and mailing your data sets will take less time than uploading your files in any other way. Approximately, you’d better consider this option when the size of your data is larger than 100 GB.
- When shipping an external hard drive with your data will remain cheaper than upgrading your connectivity (in case you’re planning to move your data online).
8) AWS Snow Family is another offline solution, composed of three different transfer services (AWS Snowcone, AWS Snowball, and AWS Snowmobile). The idea is similar to AWS Import/Export Disk, but this time you use AWS appliances to move your large-scale data.
You order the service online through AWS Console, copy your data to the device, and return it once the upload is completed. The whole process takes about a week, shipping and data transfer included. But with this option, you can move from a few terabytes to petabytes of information.
When to use this solution?
- Again, when the waiting time for shipping and transferring data is justifiable as compared to any other upload method.
- Choose between AWS Snowcone, AWS Snowball, and AWS Snowmobile, depending on the volume of your data. AWS Snowcone is the smallest physical storage in the AWS Snow Family. It’s easy and portable, and users order Snowcones for data transfers, the same as in cases of connectivity issues.
- AWS Snowball is for more large-scale migration of data (from 42 TB). And finally, AWS Snowmobile is a whole shipping container. With this service, you get more secure, high-speed data transfer, GPS tracking, video surveillance, etc., etc.
In case you want to go deeper in the variety of Amazon S3 transfer acceleration tools, don't miss our post on this topic.
Common issues and solutions
Amazon S3 attracts users with its many benefits. The storage is durable, has unlimited storage abilities, and has unique security opportunities. Although most of the time it’s a sheer delight for you to work with this storage, disruptions still happen.
Here’s how you can solve them:
Problem 1: Your access to the storage is denied.
Solution 1: This means you’re using the wrong access key and/or secret key, or you may simply have no rights to access the storage. Check your credentials as well as the permission policy to your IAM user if this is applicable.
Problem 2: Your specified key doesn’t exist.
Solution 2: You receive this message if there are issues with the naming of your files and buckets. Check the names, remove punctuation, and special characters if present.
Problem 3: Your signature doesn’t match.
Solution 3: If you see this error message, it’s likely that you used capital letters and/or spaces in your bucket name - rename the bucket. Better yet, create a new one with proper naming conventions).
Problem 4: Your files don’t upload/download.
Solution 4: Check your internet connection and/or speed. Remove the cache. Make sure you have free space in your storage, and that your uploads meet Amazon S3.
Then you may need to check your host settings: go to Downloads - Settings - Extensions - Amazon S3. Is your host set up correctly? The region? Review the filenames of your files (the number of characters and whether they have any special characters, for example). If you’re using a mobile device, check the size of your photo/video - it should not exceed 2 GB.
Problem 5: When your files grow in number, you’ll notice soon it becomes more difficult to manage them.
Solution 5: Digital Asset Management can enhance your Amazon experience and resolve this issue for you.
Advanced file organization with Pics.io DAM
Move your S3 storage to a whole new level by integrating it into Pics.io DAM. This is an advanced solution for organizing and distributing your files so as to maximize your team’s performance.
Pics.io DAM is a win-win strategy for you as an Amazon S3 user. Since it works on top of your storage, you won’t need to use extra software (and migrate your files again). No one will have access to your storage, & no charges for storage space. You get:
- Unique file organization. No need to search your storage for hours or cram all those prefixes. Pics.io displays your S3 storage in a more usual and user-friendly way so you can navigate it easily. Plus, it is very visual - you can actually see all the thumbnails, and it saves a lot of time in daily work.
- Access. With DAM, you access your files very easily by keywords, locations, dates, and so on. Or you may use the more advanced search: for example, you can find your files by content with AI-powered search.
- Collaboration with your team. Your colleagues can leave you messages under specific assets or mark the areas they want to discuss. Tag your teammates directly in your storage. And get updates on any changes in the directory.
- Sharing. With Pics.io DAM, you have unique shareable websites where you place your materials and then send the link to your clients/freelancers/partners. Customize these websites: for example, add your domain name or change the color palette to promote your brand.
- Security. Add one more level of security to your storage by changing rights and permissions. For example, you can specifically decide who can upload/download your assets, edit, and delete them. And many other pleasant surprises like linked assets, a file comparison tool, a communication center, etc.
Planning to be included in Amazon listing? Don't miss our overview of the most common Amazon Listing Optimization Mistakes and how to avoid them.
Last but not least, if you had tried multiple public cloud providers, but still decided to stop on Amazon S3, this obviously happened for a reason. With its scalability, convenience, and security, Amazon S3 is indeed one of the leading storages available on the market today. In turn, our Pics.io team will help you to make the most out of your storage and enhance your Amazon S3 experience.


