
In this article, you’ll learn:
What is S3? When you only start with it, it doesn't seem that intricate. Just storage is all. But as you delve deeper...console, access key, buckets, objects. What else would you bump into instead of "normal" files and folders?
Yeah… AWS has somewhat of a learning curve. More advanced configuration options compared with Google Drive. To help you with learning, we have written a guide on how to upload and manage files in Amazon S3. But there is a lot more to it.
Amazon S3 bucket is the first thing you encounter as you log in to Amazon S3. So, let's start with that: how to create and manage S3 buckets. That's what we are going to cover in this article, so stick around.
But first things first. Let's define the bucket.
Amazon S3 bucket: Definition & key terms
What does S3 Stand for?
The full name is Amazon Simple Storage Service. But that's a bit mouthful, hence the shortening to Amazon S3.
What is the AWS S3 bucket?

When you first open Amazon S3, you might be surprised by its unusual terminology. And their documentation won’t help: some sorts of buckets, objects, and many other unfamiliar terms. Amazon S3 bucket configuration and management can be complex, especially when integrating it into a serverless architecture. AWS serverless consulting services offer valuable expertise to help businesses navigate this intricacy, ensuring their data storage solutions are secure, scalable, and optimized for their specific needs.
But don’t let yourself be misled. An S3 bucket is a traditional root folder. It just works a bit differently
A root folder means the highest level of hierarchy in the folder structure. Basically, you cannot place a bucket into another bucket. And the objects (files + metadata) go into buckets.
In that sense, the S3 file isn't any different from the Drive file. Nor OneDrive folder is opposite to S3 bucket. Amazon just chose to use different names for things you are already familiar with.
Still, there are a couple of nuances you must know. S3 bucket has its specifics like regions or naming conventions (we’ll talk about all this later). The storage itself has a bit different nature – it’s object storage. Everything you upload there gets transformed and stored as objects.
But if you simplify it all, a bucket becomes a root folder that helps you store and organize your objects. And an object is simply the data you store.
What can I do with my bucket?
Buckets aren’t a parent folder that we’re all used to. Your bucket operations are somewhat limited. You can create a bucket, upload and download objects from there. You can also ask for the bucket location and a list of all available buckets in your S3 storage. Deleting and emptying your bucket is also possible.
What you cannot do:
- Move your buckets. Again, they’re NOT traditional directories so you cannot place one bucket into another, for example.
- Change the name of your bucket. These are unique & chosen once and forever. We’ll talk about it more.
- Rearrange the order. By default, your buckets go in alphabetical order. You can make them go in reversed order, but that’s it.
What is S3 bucket size limit?
Fortunately, there aren’t any size limits for your buckets. You can store any number of objects you need. Amazon doesn't put any limits on your storage space.
The only thing you should remember is the 100 bucket limit per account. Though, you could adjust this restriction by revisiting your account settings.
What other terms should I know?
Bucket policies specify S3 bucket access for individual users. Of course, no need to grant admin rights to all your users. Sometimes, read-only permissions are enough, and this is where bucket policies will come useful.
Access control lists (ACLs) also affect the safety level in your S3 storage. These let you change bucket access settings. For example, you could specify a user or a group of users and grant them access to your bucket.
But you’d better be very cautious about your ACLs. Misconfigured ACLs are a common reason for data breaches in S3 storage. And you rarely need them in practice unless you’re an experienced S3 user. As a rule, default settings should be enough for you at the beginning.
How to create an S3 bucket
Steps to create an Amazon S3 bucket
Creating an S3 bucket is actually very easy. You just go to your AWS Console, select Services. In the storage section, you choose S3. And then when you open the storage, there is a big orange Create bucket in the right upper corner of your screen.

Overall, there are two main things you need to know to create buckets in Amazon S3 – names & regions.
Naming conventions for S3 buckets
Unlike other storage solutions, S3 relies on globally unique names for its buckets. This means you cannot use the same name across different buckets. You cannot rename an S3 bucket after you created it as well.
For AWS storage, your bucket name is very important. This is a sort of identification for your data as you’ll use bucket names in URLs to access your objects. Be very careful when choosing the name and adhere to AWS naming rules and practices. Here are a few of them for you to follow:
- Use a unique bucket name across your S3 account.
- Don’t go over 63 characters, but no less than 3.
- Avoid uppercase letters, underscores, and the use of dashes/hyphens at the end or next to periods.
- Begin & end your bucket name with a lowercase letter and/or a number.
- Refrain from using any sensitive info in your bucket names like your IP address or account names. As said, your bucket name will be reflected in its URL.
An example of a valid S3 bucket name can look like this:
- myexamplebucket;
- my-example-bucket-s3;
- 3-my-example-bucket.
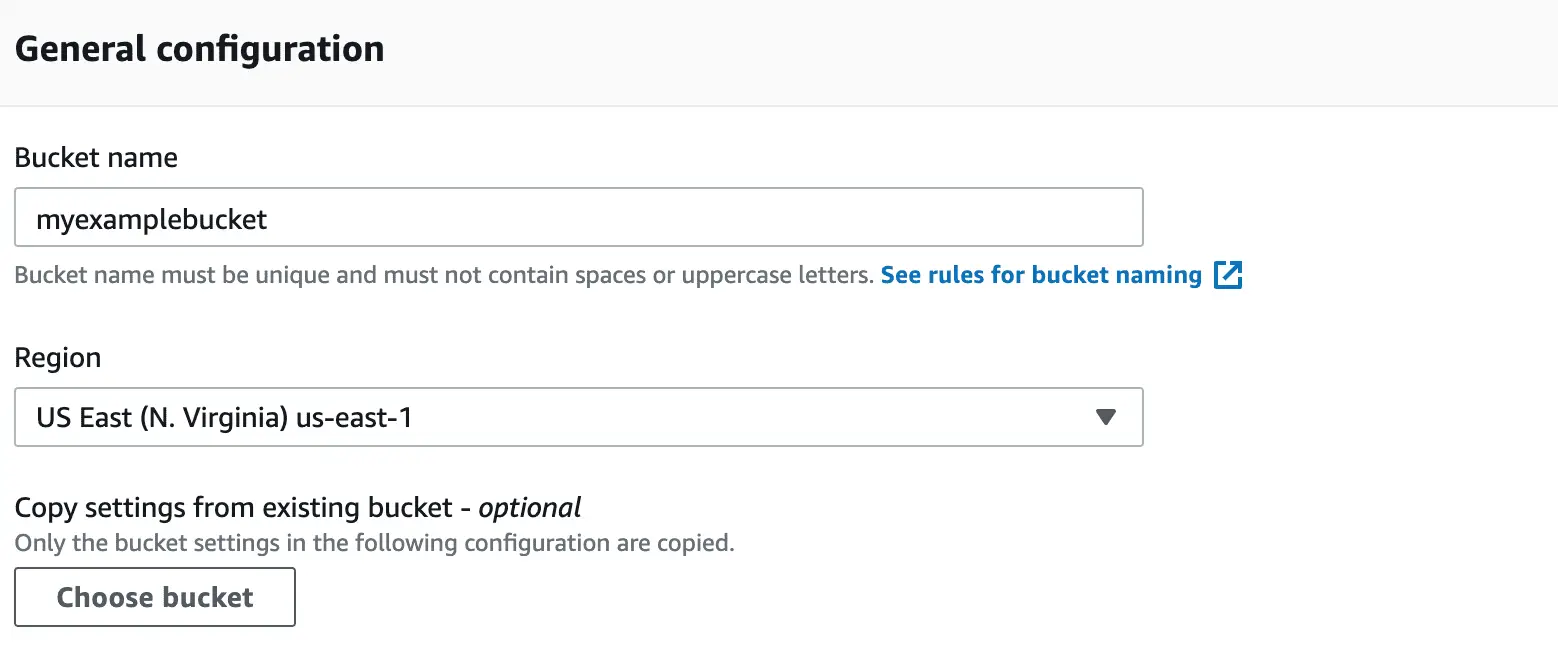
Variants like myexamplebucket.com or my.example.bucket are ok but not recommended by Amazon. What Amazon definitely won't accept are the next names:
- MyExampleBucket (uppercase letters);
- my-example-bucket- (a hyphen at the end);
- My_example_bucket (underscores).
And what about S3 bucket regions?
An opportunity to choose the S3 bucket region is another unique feature of S3 that competitors don't have.
Yes, you must specify the region where you want to store your objects. And try to be as selective as possible since this will impact the costs, latency, and even regulatory requirements to your storage.
As a general guideline, Amazon recommends choosing the region that is the closest to you geographically. If you are in Europe, choose between Europe (Ireland) and Europe (Frankfurt) regions. That way, you’ll reduce your expenses & improve the performance of your AWS storage.
Amazon S3 bucket security
During your bucket creation, you’ll meet a few blocks of security settings. The safety & security of your storage will depend on how you configure your buckets.
Fortunately, your S3 storage provides strong security settings by default, similar to any other Amazon-driven service.
Data leaks still happen, though. 198 million US voter profiles that were stored in Amazon S3 went public in 2017 because of the insecure S3 bucket. In February 2020, the English care home reported the leak of 10,000 resident records caused by the same mistake.
If you don’t want to be the next headline in cybersecurity news, you’d better secure your AWS bucket. Let's talk about three specific ways how to achieve this.
1. Manage your bucket permissions
- IAM (Identity and Access Management) policies are the most general access rules applied to the whole AWS Cloud. They impact your buckets rather indirectly.
- Then come bucket policies, which center around the data in your buckets. For example, you can grant your users read (= viewing) and/or write (editing, uploading, deleting, etc.) permissions.
- With Access Control Lists (ACLs), you manage access to your resources (buckets & objects). You choose specific users who can access your buckets & the type of access they would have.
- Query string authentication & URLs-based access is a way to provide temporary access to your buckets. For example, you need to grant one-time access to your partner so they could upload the materials. And so you provide permissions based on a specific URL.
Fortunately, Amazon S3 has good security measures by default. So if you’re creating the first bucket in your life, you can omit the permission section before you learn it better.
2. Be cautious about S3 bucket public access
When creating an S3 bucket, you can set it public or private. Public access means that everyone can access your bucket on the condition that they have its URL.
You might ask who on Earth would want their private info publicly accessible. Sometimes, you still need it like when a photographer needs to share raw files with the client. And it’s much simpler to provide a link to the bucket where photos are stored than to send them one by one.
But this example is more an exception rather than the rule. In most cases, companies want their materials to be private & secure, while public access is a recipe for blunders.
So, be mindful when choosing between private vs. public access. Again by default, all Amazon buckets are private:
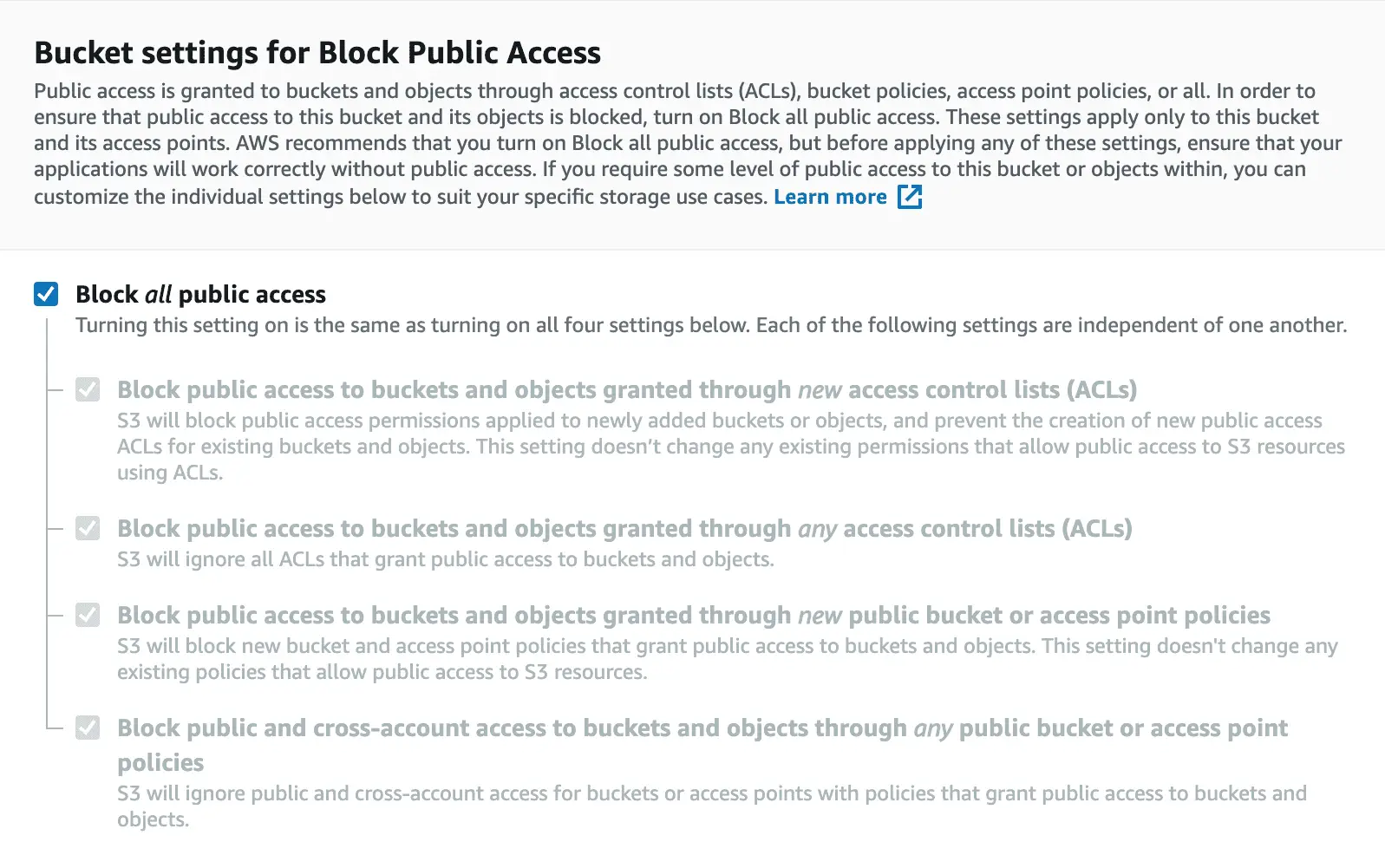
And even if you uncheck the boxes above, you’ll have to go through a range of steps to set up a publicly accessible bucket. For one thing, AWS will give a warning message concerning public access to your bucket:

According to S3 policy, the storage recommends avoiding public access unless you have very specific goals. For another thing, you’ll have to be very careful what public access settings you need. For instance, you could restrict public access to new ACLs only.
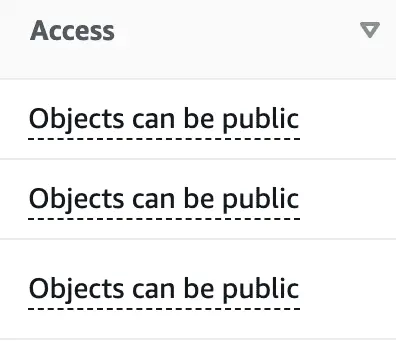
By the way, it's easy to check whether your bucket is private or public. Just see the access column in your S3 window:
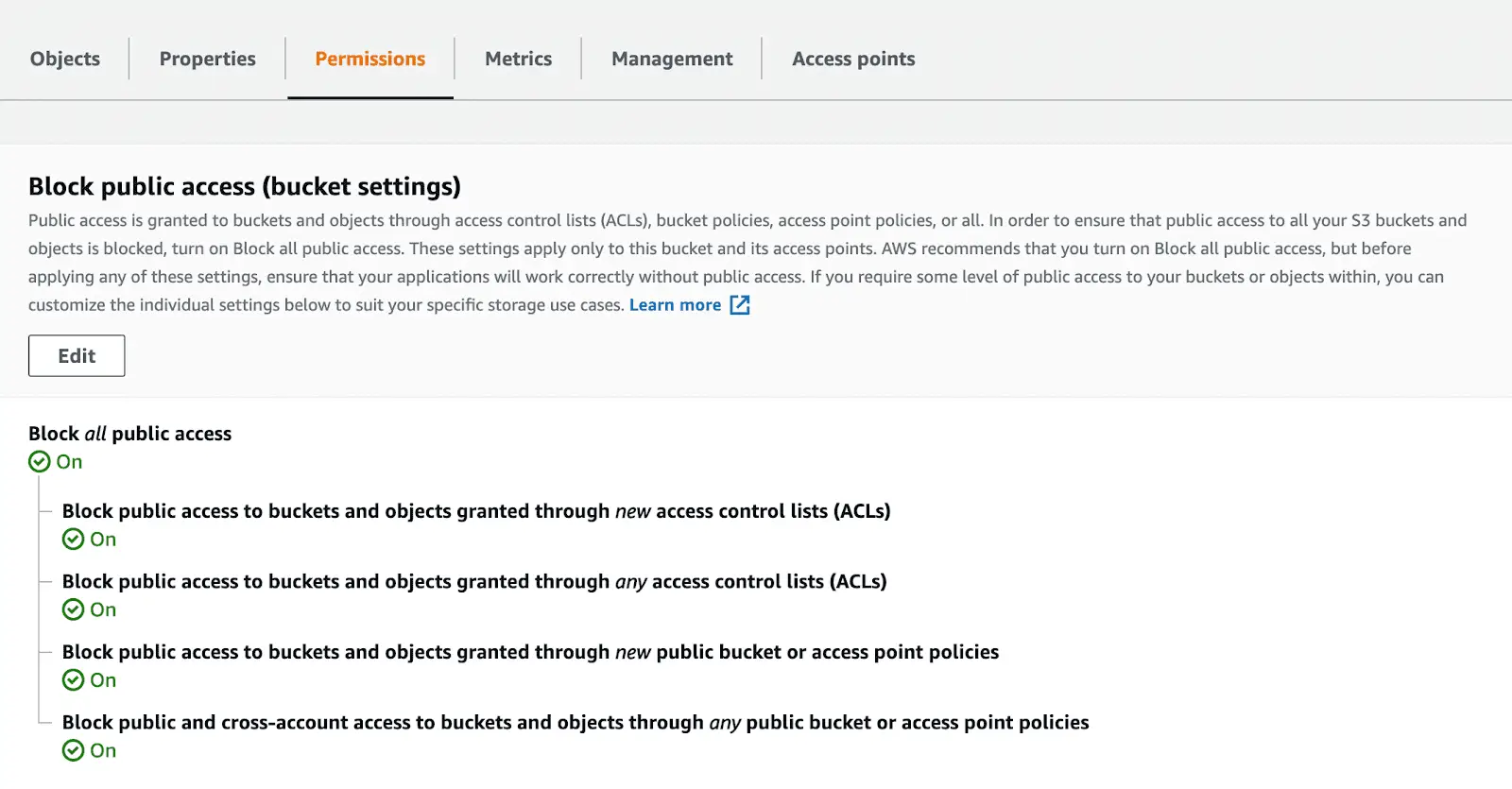
In your Console, you can also edit public/private access if needed. Just choose the needed bucket in the list. Then click Permissions > Edit > Block all public access (or tick the one you need) > Save.
3. Set up encryption
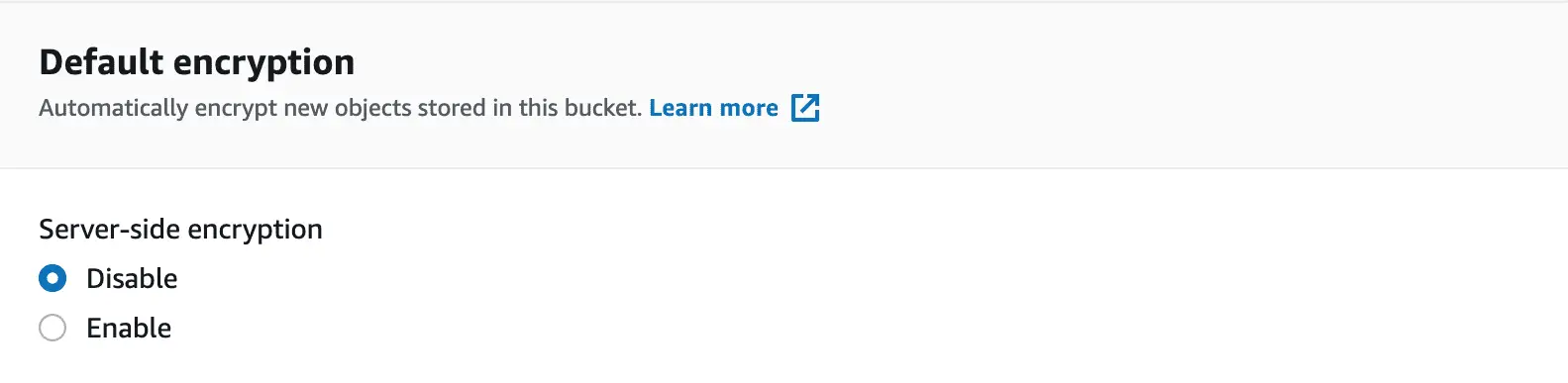
One more awesome thing about Amazon S3 is default encryption. This is one more layer of protection for your data, preventing hackers from accessing your info.
But don’t be confused by the “default” term. In S3 storage, you have to enable default encryption to make it work. This is one more thing you set up when creating a bucket:
How do I know my S3 buckets are secure enough?
One of the primary benefits of S3 is its compatibility with other tools. And security isn’t an exception here. Wanna be sure that your buckets are safe & private – use the tools available to you.
For example, Amazon offers you several cloud-native options to track access to your S3 buckets:
- AWS CloudTrail will help you record & see your bucket-level actions.
- AWS Config is a service to monitor your AWS configurations, such as ACLs and bucket policies to prevent any policy violations.
- Developed for more tech-savvy people, AWS Cloudwatch shows you resource utilization across your AWS account, Amazon S3 included.
- AWS Trusted Advisor provides you with real-time data regarding your AWS infrastructure, security, costs, and performance. But the best news here is available AWS Trusted Advisor S3 Bucket Permissions Check, which became free of charge in 2018.
Also, consider incorporating third-party tools, which won’t cost you an arm and a leg as compared to official Amazon services. Different cloud management platforms like Arcus or Dynatrace will scan your buckets & inform you about any potential threats timely.
Upload objects to your Amazon S3 bucket
Your bucket is ready. Our next step is to upload objects there. Just returning to S3 terminology, there are no files in your S3 storage – only objects. These are composed of files, plus their metadata (optionally), and could be of any format you know: text file, image, video, audio, etc.
So go to your bucket list > select the bucket > click on Upload. Now you have a couple of options: you can drag-and-drop your files or point-and-select them with the Add files.
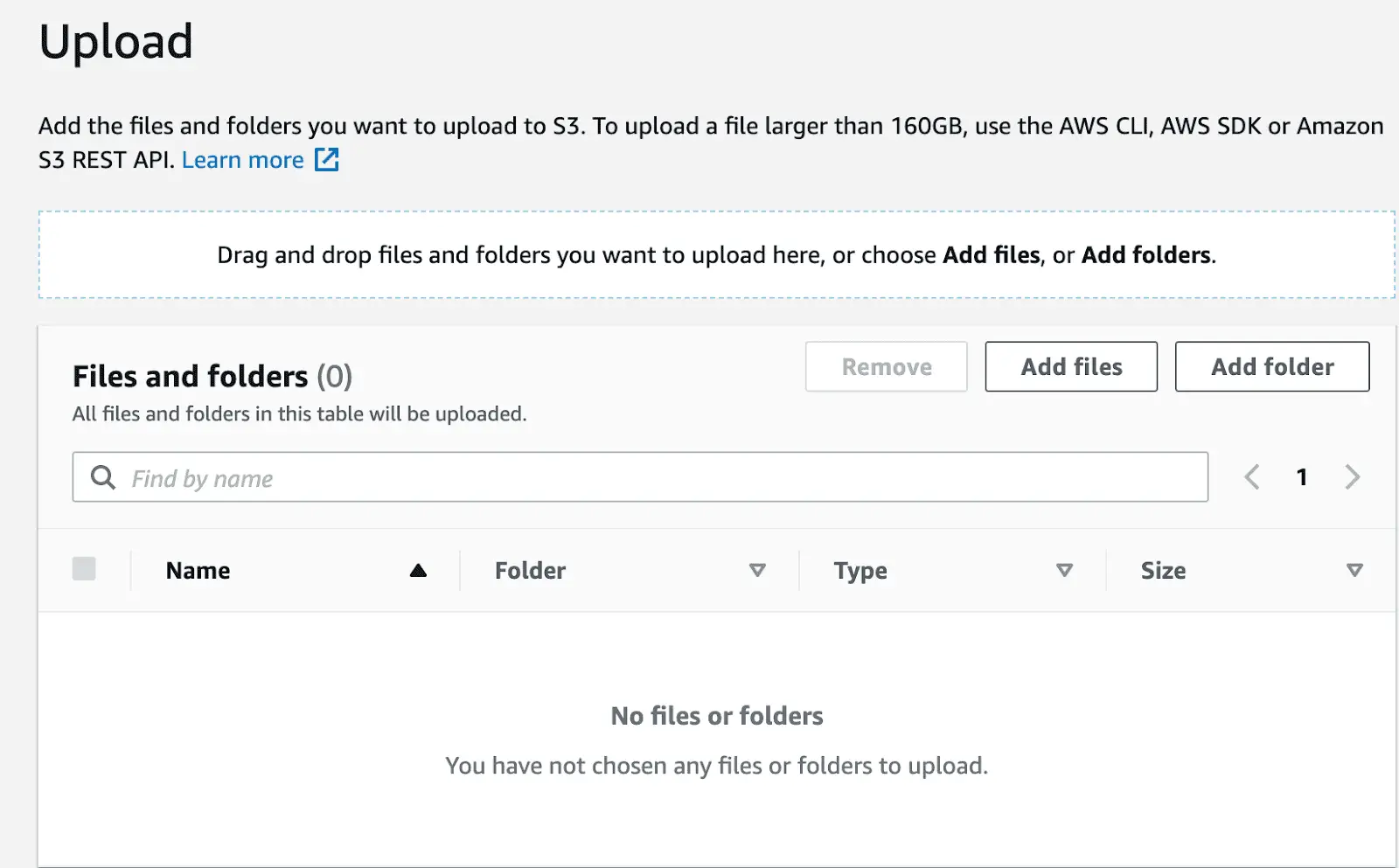
You can also upload your files one by one or do whole folders at once. The good news is that Amazon S3 mirrors your folder structure. So you won’t spend all day putting your objects in proper order.
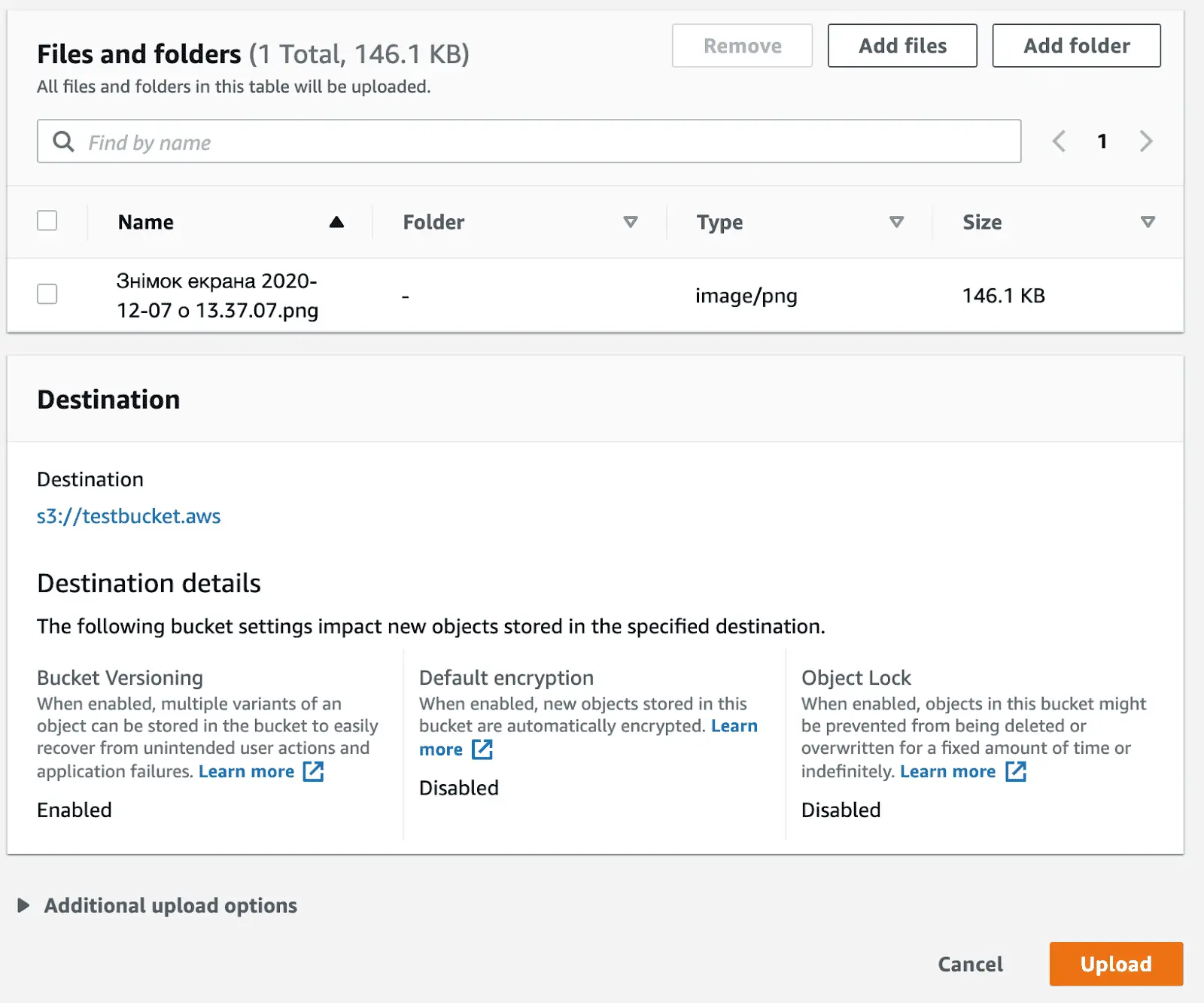
During the upload process, you can check the destination of your files one more time as well as the details. Destination details depend on those settings configured for your buckets originally, for example, chosen encryption or versioning. Don’t forget to save your results with the Upload in the bottom part of your page.
Read also about Amazon S3 acceleration tools to upload files faster to the AWS storage.
S3 bucket access & downloading the objects
How to access your S3 bucket?
Amazon S3 Console is your main tool to manage your buckets. There you can perform any bucket operations without writing a line of code. So you just open the console & see all your buckets.
Still, there are alternative ways to access your buckets. And these are less time-consuming & save you from repetitive tasks.
For example, you might choose to access your buckets through so-called bucket URLs. Amazon S3 supports both virtual-hosted & path-style URLs so use whatever is more convenient for you.
A virtual-hosted style allows you to customize your URL as your bucket name goes first. In this case, your bucket URL will be website-like:
- http://testbucket.aws.s3-us-west-2.amazonaws.com, where testbucket.aws is your bucket name & us-west-2 is your region.
In path-style access, the subdomain is fixed (s3.amazonaws.com) & you cannot change it to your own needs:
- http://s3.amazonaws.com/testbucketl.aws, where testbucket.aws is your bucket name.
OR
- http://s3-us-west-2.amazonaws.com/testbucket.aws, where testbucket.aws is your bucket name & us-west-2 is your region.
If you’re using other AWS services, there is even an easier way to access your bucket through S3://bucket. Just use the following URL:
- s3://testbucket.aws, where testbucket.aws is your bucket name.
How to download from an Amazon S3 bucket?
The same as uploading, downloading objects should be as easy as ABC for you. Go to your bucket list & select the one you need. Then multi-select the object(s) > click Actions > Download / Download as.
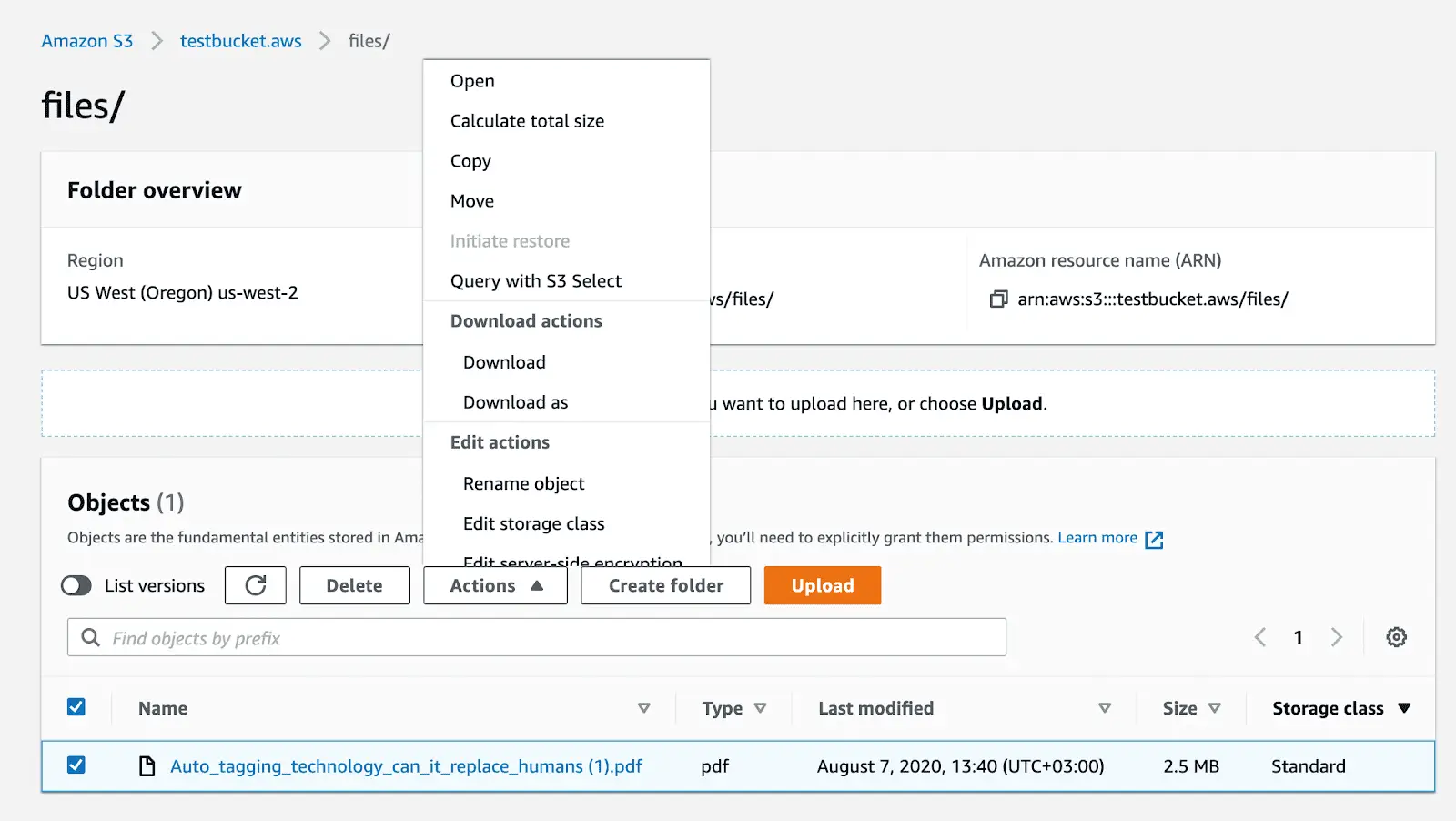
As usual, you’ll have to specify where you want to download the object & then save it.
You cannot download batch objects from the AWS Console. Downloading multiple files is possible only through the AWS Command Line Interface (AWS CLI). This is an open-source tool, enabling you to run commands to interact with AWS services. But as you understand, you’ll need some basic knowledge of technology in this case.
Note: you cannot preview objects in Amazon S3 like in similar cloud storage solutions. Stored as objects, your materials look all the same, regardless of their content or format.
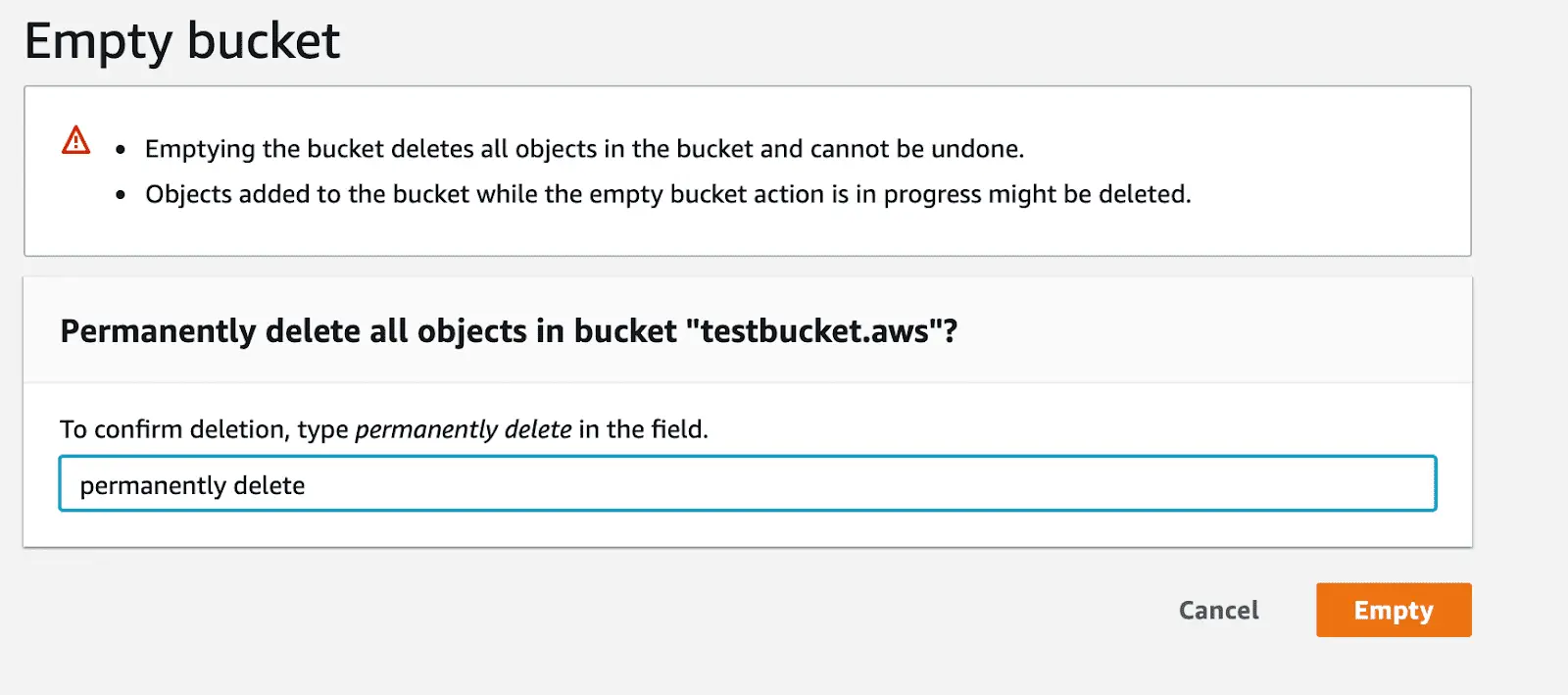
How to empty the S3 bucket or delete it?
To empty the bucket, you choose the right bucket in your bucket list & then click Empty. Then, you’ll be asked to type permanently delete in the field to be able to empty the bucket. Press Empty – and all your objects will be deleted. Don’t forget that versions will also disappear if you enabled versioning for your bucket.
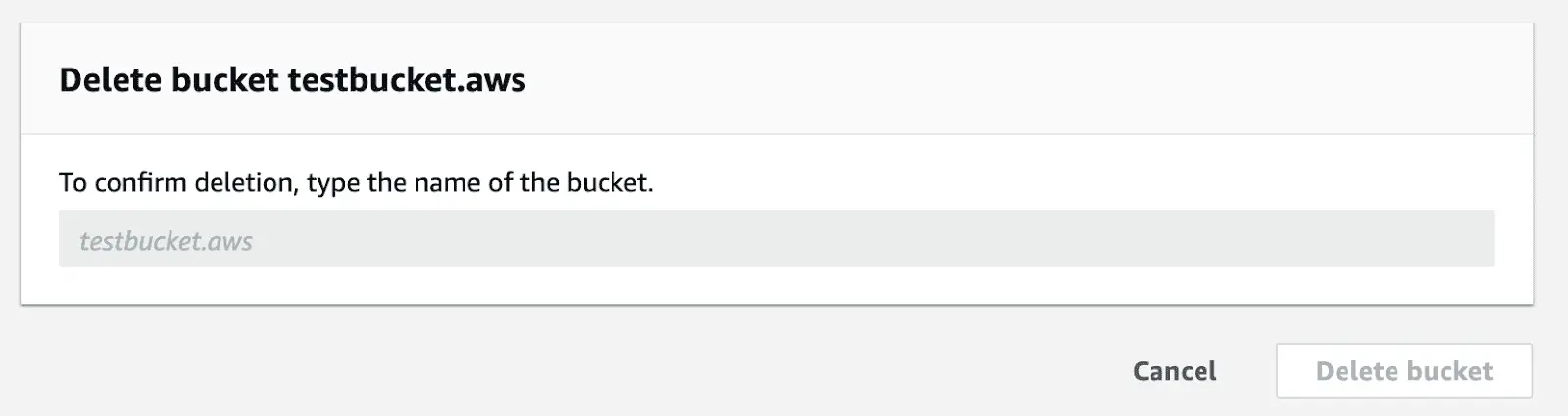
The deletion procedure is very similar. There are a few things to remember:
- You can't delete a bucket unless it’s empty.
- You can reuse the bucket name when the bucket is deleted. But if you’re planning to use the same bucket name any further, it’s better not to delete the bucket. Just empty it.
- Amazon warns you that some issues could appear preventing you from reusing the name. For example, it may take some time before the name will become available to you again.
To delete the bucket, go to the list of buckets > select the one you need > click Delete. Then you’ll be asked to type the bucket name to confirm the deletion. Finally, click Delete.
Advanced S3 bucket settings
There is a whole list of additional features you can set up for your Amazon S3 bucket. You add those during the creation process. Or just go to the Properties when your bucket is ready.
So what can you add/change here?
- Versioning will be a real finding for you in case of accidental overwrites or deletes. This is also a good help to avoid duplicates.
- Server access logging will help record & monitor access requests to your buckets. With this functionality, you get updates on who requested access to your bucket, what bucket it was, when it happened, and the response status.
- You can use your bucket for static website hosting to store your website content.
- Default encryption will help you secure your data.
- Object locking is a useful feature to prevent your objects from being mistakenly deleted.
- Allocate your costs, categorize, and manage them with tagging.
- Transfer acceleration is a relatively new feature added to provide you with fast & secure data transfers to & from your buckets.
- Enable events if you want to receive notifications about any updates in your buckets.
- By default, the bucket owner takes responsibility for any payments in Amazon S3. But you can change it with requestPayment so the storage will charge users for downloads from your bucket.
- Plan the lifecycle of your objects ahead. With this feature, you can archive your objects after some time, delete them in 5 years after creation, etc.
- Replication will make your life easier if you need to copy objects across buckets. This configuration will help you do it automatically & effortless.
Wrap up
Amazon S3 makes up a perfect solution to scale your files & don’t overpay for space. Plus, it’s highly compatible with other Amazon services and its infrastructure, which many businesses choose for developing their applications.
A steep learning curve is its only disadvantage. But we’re not afraid of difficulties, are we? Amazon S3 is a perfect solution – just many things that we’re used to are a bit different.
This is actually why we prepared this post. If you follow our instructions & go point by point in bucket creation or management, you won’t meet any difficulty. And you can always peep at our detailed Amazon S3 guide to familiarize yourself with S3 infrastructure.
And don’t forget that you can power up your S3 storage with an advanced digital management tool. Tagging & metadata, shareable assets & public websites, advanced search capabilities, and anything you need to manage your data the most productively!


